



NVIDIA GeForce GTX Titan显卡深度评测
2013年2月21日,NVIDIA正式发布了新一代显卡。没错,它就是传闻多时、采用GK110核心的GeForce GTX Titan。它和GTX 680一脉相承,都源自Kepler架构。尽管它们是同门兄弟,但GTX Titan才是Kepler架构的真正代言人,它才能代表Kepler架构的真正性能,并开启了一个全新的单核心显卡时代。

从名称来看,新的GeForce GTX Titan(下简称“GTX Titan”)不存在于任何NVIDIA现有的产品序列中,完全是一款独立的显卡。这样的事情在近几代GPU产品中还是“大姑娘上轿———头一回”,这里面有什么隐含意义呢?
实际上,这样的事情在CPU领域已经有过先例。AMD在K8时代推出过Athlon FX处理器,专门针对顶级玩家,英特尔也有PentiumXE系列产品与之对阵。顶级产品一般有如下特点:首先是无与伦比的性能,比如Core i7 3970X,性能明显超出目前所有民用市场的处理器;其次是高昂的价格,一般定价999美元显得理所应当;第三则是单独的产品序列,比如英特尔为顶级CPU启动了LGA 2011接口,配置了X79芯片组。
GTX Titan走的也是这样的道路。NVIDIA可能认为泰坦本身的性能和其代表的技术实力已经无法放置在目前已有的显卡序列中,因此需要为其单独划分一个顶级型号来做出区别——至少这款产品已经满足了顶级市场的三个特点中的两条:高昂的售价和明显超出目前民用级别GPU的性能。至于独特的接口则考虑到显卡受限于PCI-E规范,暂时无法做出任何改变。即便如此,GTX Titan单核心卡皇的定位已经毋庸置疑。

GTX Titan架构浅析
NVIDI A在GTX Titan上使用的核心依旧是GK110。有关这颗核心的详细内容,本刊在2012年9月上、下两期的《巨兽来袭 开普勒GK110全面解析》系列文章中已经给出过详细的解读,欲了解这颗核心有关架构设计和功能设计方面的详细内容的读者可以翻阅此文。在此,本文仅给出GTX Titan比较简略的架构参数等内容。
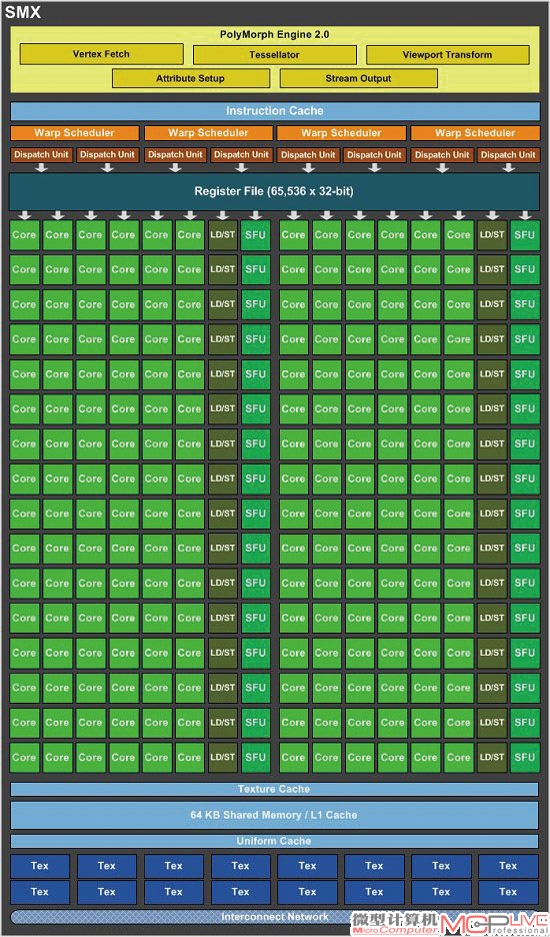
GTX Titan采用的GK110核心内置71亿个晶体管,拥有15个SMX单元,每SMX单元有192个(统计意义上的)CUDA Core和16个纹理单元。具体到产品上来,GTX Titan基于NVIDIA Kepler架构,采用第3.5代SMX技术(GK104为第3代),有14个可用的SMX单元,总计2688个CUDA核心、224个纹理单元以及48个ROP单元。GTX Titan的基础核心频率为837MHz,Boost频率为876MHz(实际上是可变频率,此处仅为官方公布的基准数据),单精度计算能力为4.5TFlops,双精度计算能力为1.3TFlops(GTX 680的单精度能力为3.09TFlops,双精度仅为0.13TFlops),显存采用6008MHz的6GB GDDR5,位宽为384bit,带宽为288.4GB/s。技术规格上支持PCI-E 3.0、DirectX 11.1、Shader Model5.0、OpenGL 4.3、Open CL 1.2,官方公开报价为7999元。
从硬件角度、特别是从NVIDIA给出的简略结构图来看,GK110有点像GK104的简单放大版本。不过,经过详细比较就会发现GK110和GK104还是存在着诸多差异:
1.GK104的SMX中全部都标识了绿色的CU DA Core,但是在GK110的SMX中除了绿色的CUDA Core外,还有黄色的小格子。不过暂时没有资料说明其具体功效,据猜测有可能是额外增加的双精度计算单元。
2.在GPC层级,整个GK110一共设计了5个GPC,每个GPC有3个SMX,一共15个GPC,与之相对的是GK104每个GPC只有2个SMX,一共4个GPC,总计8个SMX。
3.GK110的二级缓存增大到1536KB,相比之前GK104的512KB大大提升。二级缓存能有效地增加GPU在并行计算时的效率,但随之而来的数据命中率等问题也会“令人头疼”。NVIDIA在GK110上设计了1.5MB的二级缓存,虽没有常见的CPU 2MB的二级缓存那样多,但NVIDIA也必须主动改善缓存数据命中率才能获得更好的效能表现。更大的缓存在原子操作上的帮助极大,也是并行计算性能改善必不可少的部分。
4.GK110拥有6组显存控制器,对应着6组ROP单元(每组8个,共48个ROP单元)。相比之下GK104只有4组显存控制器和4组ROP单元。GK110拥有更大的显存带宽、更多的ROP单元和容量更大的显存意味着GK110在高分辨率、高画质以及高抗锯齿等超高游戏设置场景下有更宽裕的资源和更强大的性能表现。
这样来看,GK110不太像是GK104的放大版,毕竟无论如何放大都不可能放大出如此多的“额外单元”和“额外能力”来。实际上GK104更像是GK110的精简缩小版,这就意味着GK110先完成设计定稿,GK104随后才精简上场。也可以从另一个角度来对比GeForceGTX 680和GTX Titan:从硬件基础来看,GTX Titan基准频率是GTX 680的83%、流处理器数量是GTX 680的175%、显存带宽是GTX 680的150%、计算规模(单精度)是GTX 680的146%。如果没有特殊设计,GTX Titan的性能应该能达到GTX 680的140%左右。当然,在当前工艺下,越接近工艺极限,性能提升越困难,成本就越高。为了这后“40%”的胜出幅度,GTX Titan的价格超出GTX 680 142%。
此外,从“体积”角度来看,GK110的核心面积高达551平方毫米(GTX 680仅为294平方毫米、GTX 580则有520平方毫米),是目前面积大、晶体管多的GPU核心。GK110延迟发布的好处在此刻也显现出来:TSMC和NVIDIA有长达一年的时间来调整工艺、提高良率并囤积芯片。因此GK110本身无论在频率表现和功耗控制上都显得更为成熟。历史上也从没有这样一大核心GPU的频率能达到至少876MHz,多接近1GHz(GPU Boost高频率高达992MHz)的程度,并且它的功耗表现在各种辅助技术的帮助下竟然被压制在TDP250W的状态,这不得不令人惊讶。
对比完GTX 680,如果一定要为GTX Titan找个“影子兄弟”的话,早在去年年中发布的Tesla K20X和GTX Titan堪称真正意义上的“双子星”,比如GK110所拥有的Hyper-Q以及Dynamic Parallelism动态并行技术在K20X和GTX Titan上全部具备,没有任何削减。一度传言GTX Titan将削减双精度也被证实为谣言。NVIDIA给出的GTXTitan的晶圆照片和架构简图也和之前公布Tesla K20X的时候完全相同。可以认为,GTX Titan除了为GeForce玩家设计、面向游戏领域外,其余部分几乎和Tesla K20X完全相同。

流传于网络的GK110晶圆照片,其核心规格和我们的预估一致。

GK110的核心架构,实际上为了良率考虑,GTX Titan被屏蔽了一组SMX。

NVIDIA给出的GTX Titan和英特尔Core i7 3960X处理器的计算能力的对比
用于提升效率的Dynamic Parallelism、Hyper-Q
GTX Titan的CUDA Core数量众多,架构复杂,如何提升执行效率、从而避免因为核心规格大幅增加导致效率降低呢?主要的就是GTX Titan新加入的Dynamic Parallelism、Hyper-Q机制。在传统的GPU-CPU的计算架构中,CPU往往用于控制、逻辑处理等,自己贡献的计算能力不多,GPU则会利用大规模并行计算能力提供强大的计算性能。在这种系统中,GPU需要在CPU的控制下才可以运作。举个简单的例子,在CUDA执行中,Femri的任何一个Kernel只能由CPU给予,自己基本无法执行判断和逻辑操作,即使这个逻辑非常简单(Kernel是CUDA的专用数据,汉译为“核心、要点”)。这种GPU和CPU的紧密相关性,让CPU在很多情况下占用率变高,对CPU的性能也有一定要求。实际上这种简单的判定工作需要的处理电路并不复
杂,于是NVIDIA在GK110上加入了Dynamic Parallelism动态并行控制技术,使得CPU的工作被大大简化了。
这样的过程变得更为清晰简单,在整个工作流程中,CPU只需要关心开始和结束,对中间的内容几乎不需要参与。这可以节约大部分CPU的工作量,让CPU去进行更复杂的任务或者干脆使用一颗性能较低的CPU即可完成。此外,动态并行控制可以让GPU在同时间内启动更多的计算进程,并且能够自我判断、自动控制计算,也能为程序人员节约大量的时间。
传统的多核心CPU在和GPU沟通工作任务时存在一些问题。
举例来说,在Fer mi架构上,Fer mi架构支持多1个信息传递界面(Message Passing Interface,简称为MPI),只能接受来自于CPU的一个工作任务。
在GK110上,NVIDIA使用了名为Hyper-Q的技术来大幅度提高CPU的效率和GPU的占用率。Hyper-Q的主要改进在于增加了CPU和GPU内的CUDA Work Distributor(直译为CUDA工作分发设备,简称为CWD)之间的链接总数。再加上其他的改进,新的GK110可以接受来自多个CUDA命令以及MPI的进程,甚至一个进程内部的多个工作执行单元都可以在新的GK110上并行执行。现在GK110可以执行多32个并行的MPI。 为了达到这个目的,每个CUDA进程的内部工作序列管理,以及相依关系等需要重新处理以达到佳化,并且GK110在某个进程内部的计算不会扰乱或阻挡其他进程。不同进程如果不存在严格的相依性,也可以同时并行执行,大大提升了效率。
、GK104的SMX对比。")
、GK104的SMX对比。")
更智能的加速——GPU Boost 2.0
在CPU上,智能加速已经是被普遍使用的技术。在GPU上,这项技术也只有在NVIDIA发布GTX 680后才开始正式出现。GTX 680是首次真正尝试在硬件部分加入监控和调整功能并设计了智能加速功能的产品。在GTX 680以及随后的显卡上,NVIDIA对显卡的频率设置了三个门槛,分别是基础频率(base clock)、加速频率(boostclock)和大频率(max clock)。
基础频率就是GPU的默认核心频率,比如GTX 680是1008MHz;加速频率是指GPU在Boost状态下的参考频率,GTX 680是1058MHz,大频率则是GPU在使用中、在高电压(Vrel释放电压)下可能达到的高频率。在NVIDIA给出的参数中往往只公布基础频率和加速频率,而大频率一般都不会明确标识。在使用过程中,GTX 680的核心频率会在1006MHz到大频率之间不停地变动,这个变动是根据GPU的运行状态进行适时调整的。由于这种变化的存在,加速频率1058MHz其实更像一个参考,它表示的是在大部分情况下GPU Boost可以提升的频率以及相应的性能增长情况。但是根据软件的不同,GPU的频率甚至可以上升到1100MHz或者更高。
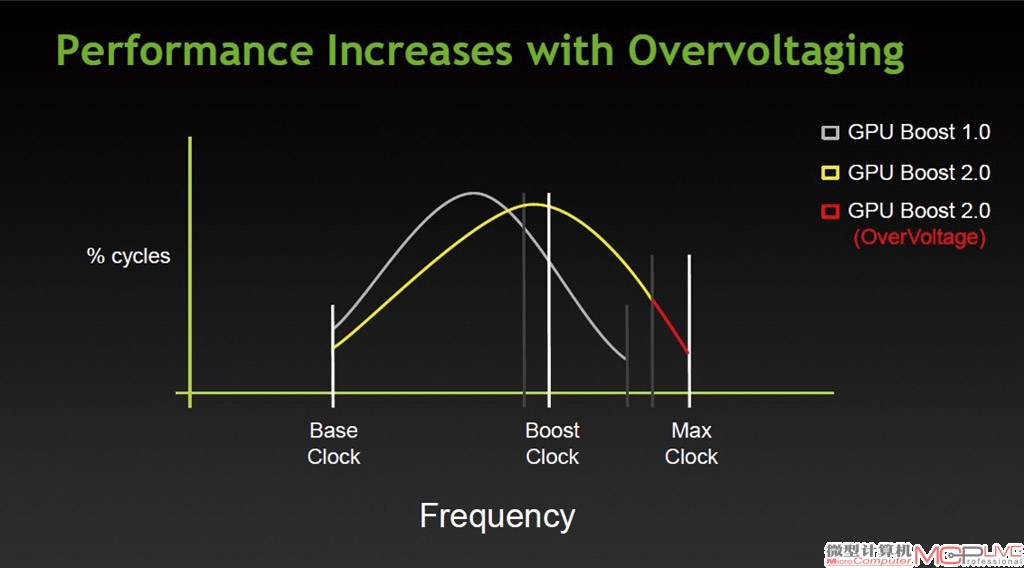
GTX 680以及随后的显卡配备的GPU Boost技术被称为GPUBoost 1.0。在这个版本中,Vrel实际上是NVIDIA设置的一个无法逾越的鸿沟,NVIDIA认为电压和频率超过Vrel的相关值可能会对GPU部分元件产生不可逆的损害。但随后发现,GPU在短时间内特别是温度控制适宜的情况下,超过Vrel是可以被接受的,也没有产生明显的损害。特别是在GK110这种大芯片上,本身频率和电压都不高,距离晶体管极限值还有一定距离,只要温度控制得当,就能够在短时间内获取更高的频率、更快速地完成工作任务。这就是GPU Boost 2.0的由来。
在GPU Boost 2.0中,Vrel不再是绝对上限无法逾越。NVIDIA新设定了Vrelnew以及Vmax。Vmax和Vrelnew都高于之前的Vrel。尤其重要的是,NVIDIA加入了一个重要参数——GPU温度。NVIDIA为GTX Titan确定了80℃的高温度。在显卡运行中,如果温度高于80℃,那么显卡会以较高的幅度提升风扇转速,并同时降低频率、电压等确保GPU工作在安全温度内;如果GPU侦测到温度低于80℃,那么GPU会自动上调电压到Vrel甚至Vrelnew。此时频率会进一步小幅增加,用户可以获得比传统GPU Boost 1.0更高的频率和性能。如此反复,在温度这个大前提下,GTX Titan能够获得比传统的固定频率以及之前的GPU Boost 1.0更好一些的性能表现。在实际使用中,如果不超频也不更改电压设定的话,GTX Titan由于80℃温度监控的存在,会维持在一个很不错的静音和散热状态。
现代的GPU设计已经成为一个庞大的体系工程,其中涉及到GPU内部方方面面。除了类似FurMark这样专门“为压榨而压榨”的软件外,其余的绝大部分应用,特别是游戏类应用,是不可能让GPU全面处于高压力的满载状态的。GPU内部在正常工作情况下,有负载高一些的部分,也有负载低一些的部分,这就为GPU Boost这类应用留下了空间。如果说GPU Boost 1.0还仅仅是考虑了功耗和电压的关系、为防止GPU烧毁而做出了限制性的Vrel的话,那么GPU Boost 2.0则是充分考虑到了温度、功耗和电压,将GPU本身的运行处于动态监视之下,以获取更好的性能表现。
除了Vrelnew外,新增的Vmax更是为玩家加电压超频带来一丝曙光。在GTX 680上,加电压超频是NVIDIA严厉限制的行为,部分厂商推出的加压超频组件都由于此限制而被迫放弃。个中原因很可能是NVIDIA当时没有太好的温度监视手段,在高温度、高电压以及高频率的“三高”压力下,GPU很可能由于电路击穿、电子迁移等问题严重影响使用寿命甚至直接报废。GTX Titan的本身频率、电压都较低,如果不是考虑到TDP的限制,晶体管本身应该还能在更高电压和频率下运行。因此由于Vmax的加入,NVIDIA小幅度开放了电压上限和温度检测上限,玩家可以使用第三方超频软件来控制这两个上限并通过超频GTX Titan来获取更强大的性能。
如果用一句话来总结GPU Boost 2.0的话,那就是:温度自动控制、电压放宽区间、频率更为智能。从GTX Titan来看,NVIDIA很可能为下一代显卡全面增加类似内容,甚至推出开放电压、频率和不开放电压、频率的不同产品来应对不同市场的需求(就像英特尔在“K”系列处理器上的做法),为玩家带来更多的选择性和可玩性。

GPU Boost 2.0带来了更宽、更灵活的电压控制
显示器超频?还是更高的帧数?
NVIDIA在GTX Titan中加入了一个新的功能,叫做“显示设备超频”,这是真的吗?目前的液晶显示器的刷新率大部分都是59Hz或者60Hz,也就是说液晶显示器会在一秒钟内,使用静态刷新的方法,对显示器画面上的内容进行刷新。GPU的垂直同步功能也会将频率锁定在60Hz进行画面输出。这种刷新率在普通应用中是完全够用的,但在一些激烈的FPS游戏中,60Hz很可能会影响玩家成绩。
因此,GTX Titan新加入的“显示设备超频”可以在一定程度上缓解这个问题。在显卡连接显示器输出的时候,GPU会自动检测显示器的EDID(Extended Display Identif ication Data,扩展识别数据)信息——所谓EDID信息,是指显示器厂商在显示器内部的存储芯片中写入的显示器硬件部分的支持情况,其中包含了分辨率、刷新率等重要参数,还有色彩支持情况等不常用的内容,EDID信息就是显示器的“身份证”。GPU在侦测到显示器有关刷新率的内容后,如果显示器硬件大支持的刷新率超过60Hz,那么GPU会自动提高GPU的硬件刷新率。在打开垂直同步的情况下,GPU会自动使用更高帧率刷新输出,并要求显示器使用更高的硬件刷新帧率,这样就可以让玩家感受到更流畅的游戏体验。
举例来说,目前很多显示器都可以支持120Hz的硬件刷新率。在使用GTX Titan并启用了“显示设备超频”功能后,GTX Titan就会将垂直同步的60Hz上限提升到120Hz,并使得显示器以120Hz的硬件刷新率输出,这样显示器上显示的画面就更为流畅、自然。
GeForce GTX Titan PCB解析

接口为双DVI+HDMI+DisplayPort

GTX Titan的核心编号为GK110-400,采用A1步进。

外接供电电源接口为8Pin+6Pin

散热器使用了热均腔板技术

供电主控芯片位于一块独立的PCB上,型号为安森美 采用6相核心供电、2相显存供电设计。NCP4206,支持6相PWM供电控制。

采用6相核心供电、2相显存供电设计。
巅峰对决:GTX Titan全面测试
代表Kepler架构强性能、拥有独特命名的GTX Titan究竟在实际游戏测试中的表现如何?其性能究竟能领先定位相同的GTX 680、HD 7970多少?面对目前的旗舰级双核心产品GTX 690、HD 7990的胜算又有多少?它的通用计算性能究竟达到了什么水平?GTX Titan SLI能带来怎样的惊艳表现?接下来我们将在基于英特尔Core i7 3960X处理器的顶级平台上对GTX Titan进行测试。
考虑到GTX Titan的出色性能和定位,我们此次不仅会在1920×1080的全高清分辨率下进行测试,还会在对显卡性能要求更高的2560×1440分辨率下测试。同时,还会开启4倍或8倍MSAA抗锯齿全方面考察GTX Titan的性能。终每款游戏会在1920×1080(高画质)、1920×1080(高画质、MSAA)、2560×1440(高画质)、2560×1440(高画质、MSAA)这四种模式下进行测试。
主要测试平台
处理器 英特尔Core i7 3960X
主板 英特尔原装X79
内存 DDR3 1600 4GB×4
电源 X7-1200W
操作系统 Windows7 Ultimate 64bit
驱动程序 NVIDIA 314.09、314.07;AMD催化剂13.2Beta4
基准测试软件方面,除了3DMa rk系列测试软件、新版本的Unigine Heaven Benchmark4.0以外,我们还加入了DirectComputeBenchmark、ComputeMark以及微软DirectX SDK这三款软件对GTXTitan的通用计算能力进行测试。而在游戏方面,我们选取了6款游戏大作,除了《使命召唤:黑色行动2》(这款游戏虽然不支持DirectX11,但目前相当火爆,因此加入测试)以外,另外5款游戏均基于DirectX 11设计。我们特别加入了新发布的、有着“显卡杀手”之称的《孤岛危机3》、《孤岛惊魂3》进行测试。
GTX Titan Vs.GTX 680:理论领先幅度高达40%以上
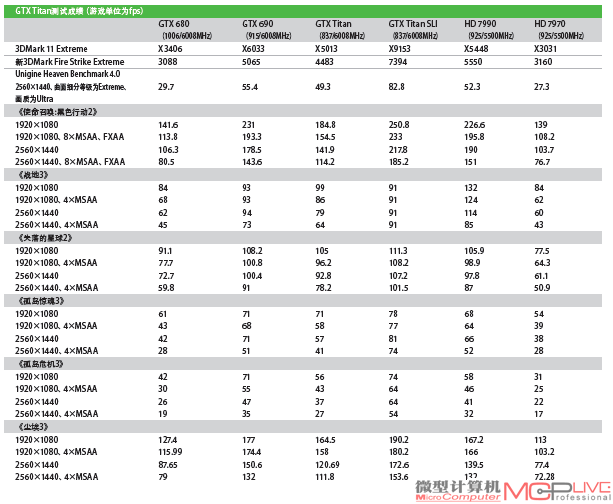
前文已经说过,GTX Titan的理论图形性能是GTX 680的140%左右。从三款图形基准测试软件的测试来看,领先幅度甚至比40%更高:在3DMark 11 Extreme、新3DMark Fire Strike Extreme、Unigine Heaven Benchmark 4.0的测试中,GTX Titan的领先幅度分别达到了47%、45%、65%。
而在实际游戏测试中,GTX Titan较GTX 680的平均领先幅度在35%左右,无法达到图形基准测试软件中的领先幅度。我们不妨从两个方面来看,一方面是由《失落的星球2》为代表的老一代DirectX11游戏,这类游戏发布时间相对较早,具有较强的代表性,没有加入太多DirectX 11的内容,在新产品的测试中优势不明显。在这类游戏的测试中,1920×1080、高画质下,GTX Titan的平均领先幅度不到20%,比如在《失落的星球2》测试中,GTX Titan的领先幅度只有15%;在1920×1080、高画质下、4×MSAA以及2560×1440、高画质下,GTX Titan的平均领先幅度在25%左右;不过在2560×1440、高画质、4×MSAA设置下,GTX Titan的384bit显存位宽、6GB显存容量的优势开始显现,平均领先幅度达到了40%左右,例如在《战地3》、《失落的星球2》中的领先幅度分别达到了42%、30%。
另一方面,以《使命召唤: 黑色行动2》、《孤岛惊魂3》、《孤岛危机3》这类新发布的游戏大作为代表,它们对GTX Titan的支持明显更好。GTX Titan在这类游戏中较GTX 680的优势已经接近40%,基本达到了理论领先水平。究其原因,这类游戏要么是NVIDIA驱动程序专门进行了特别优化,要么是游戏本身全面采用了DirectX 11的众多技术,如各种阴影、光照、离子效果和大量的Direct Compute计算等等,要求显卡具备很强的计算能力。毫无疑问,相比GTX 680,GTXTitan的“硬实力”无疑要强太多,无论是CUDA流处理核心数量、显存位宽、单精度计算能力、显存容量等影响计算能力的指标都大大超过GTX 680。因此GTX Titan在这类游戏中如鱼得水,大程度地发挥了其性能水平。
后我们想说的是,无论是以上哪种类型的游戏,GTX Titan在2560×1440、高画质、4×MSAA设置下较GTX 680的性能领先幅度都在40%以上(《失落的星球2》的领先幅度为30%)。不仅如此,在如此严苛的设置下GTX Titan的低平均帧率都在27fps以上,保证了游戏的流畅性,并不是那种“A卡帧率为12fps,B卡帧率为8fps,A卡领先B卡50%”式的毫无意义的领先。可以说,GTX Titan是目前为止唯一能在2560×1440、高画质、4×MSAA设置下流畅运行所有游戏大作的单核心显卡,具有里程碑式的意义。
GTX Titan Vs.HD 7970:压倒性的优势
正如HD 7970性能不敌GTX 680那样,GTX Titan也全面领先HD 7970,平均领先幅度达到了40%左右,优势极为明显。GTX 680相对于HD 7970的劣势在于“硬指标”不够,例如显存容量、显存位宽等参数偏低,因此GTX 680在那些运用了大量DirectX 11技术、考验显卡计算能力的游戏中开始捉襟见肘。不过它的优势是架构先进,执行效率高因此实际表现并不差。而GTX Titan在GTX 680的基础上全面提升了硬件规格,一改过去N卡旗舰显卡硬件规格不高,凭架构优势、执行效率“打天下”的惯例,在硬件规格上彻底将HD 7970击败。再加上架构上的优势,GTX Titan可谓“两手都要抓、两手都要硬”。这一点可以从《孤岛惊魂3》、《孤岛危机3》这两款新发布的DirectX11游戏大作的测试中看出来,GTX Titan凭借强大的计算能力,在这两款游戏中分别领先HD 7970高达 50%和70%左右。
另一方面,GTX Titan在大规模增加核心规格、保持对HD 7970的优势情况下,并没有出现过去AMD采用4D+1D架构的显卡一旦大规模增加核心规格后,执行效率不高的问题。这其中固然有架构先进的关系,但很重要的一点就是得益于Dynamic Parallelism和Hyper-Q技术。这两项技术让GTX Titan可以接受来自多个CUDA命令以及MPI的进程,甚至一个进程内部的多工作执行单元都可以并行执行。这增加了它的执行效率,让计算在短时间内完成。
GTX Titan SLI:理论图形性能破新高
两块GTX Titan组成的 SLI系统会有怎样的表现呢?在三款图形基准测试软件的测试中,GTX Titan SLI充分发挥了双核心的优势,性能较GTX Titan几乎成倍提升,例如在3DMark 11、新3DMark、Unigine Heaven Benchmark 4.0测试中,分别领先GTX Titan 83%、65%、68%。类似的领先幅度也出现在GTX 690、HD 7990上,GTXTitan SLI领先这两款双核心显卡的幅度也达到了50%以上。图形基准测试的结果很好地反映出GTX Titan SLI的理论图形计算能力:威力尽显,任何一款双核心显卡或者双卡系统的性能都无法与之媲美。
在实际游戏测试中,受限于驱动程序的优化、双卡执行效率,GTX Titan SLI出现了三种较为明显的状态。第一种状态是GTX TitanSLI在部分游戏中仍然有较为明显的优势,例如在《使命召唤:黑色行动2》中仍然保持了对GTX Titan 50%左右的优势。第二种状态是在部分游戏中的全高清分辨率、高画质下,GTX Titan SLI的优势非常小,甚至出现了性能下降的情况,例如在《孤岛惊魂3》、《失落的星球2》,GTX Titan SLI较GTX Titan的领先幅度分别只有10%、6%。第三种状态是GTX Titan SLI在2560×1440、4×MSAA下仍然保持了非常高的领先优势,例如在《孤岛危机3》、《孤岛惊魂3》、《战地3》测试中,GTX Titan SLI较GTX Titan的领先幅度分别高达100%、80%、42%。
GTX Titan Vs.GTX 690、HD 7990:堪比双芯显卡
众所周知,双核心产品的一大优势就是跑分,即理论图形性能很高,能够充分发挥出双核心的优势。而从图形基准测试来看,GTXTitan落后GTX 690 15%左右,而和HD 7990的差距则不足10%,甚至在Unigine Heaven Benchmark 4.0测试中性能基本持平。GTX Titan凭借超高的硬件规格,理论图形性能已经很接近双核心旗舰产品了。出现这样的测试结果也很好理解,GTX Titan的硬件规格本来就非常高,即使与双核心产品相比也不遑多让,因此在理论测试中性能差距并不算很大。
而在实际游戏测试中,GTX Titan的表现则更加惊艳。和GTX690相比,GTX Titan除了在《使命召唤:黑色行动2》、《孤岛危机3》、《尘埃3》中落后20%左右,在另外三款游戏中几乎平分秋色。和HD7990相比,GTX Titan除了在《使命召唤:黑色行动2》、《战地3》中不敌以外,在另外4款游戏中两者都基本处于一个游戏水平。前文已经提到双核心显卡的大优势在于跑分,而在实际游戏中受限于驱动优化、执行效率、游戏差异等众多因素,性能反而不如其理论图形性能,因此这两款双核心显卡的实际游戏性能差距和GTX Titan进一步缩小也就在情理之中。综合理论图形性能、实际游戏性能来看,毫不夸张地说,GTX Titan是近来首款在性能上和同时代双核心显卡如此小的单核心产品。


GTX Titan SLI的理论图形测试成绩非常惊人
通用计算:GTX Titan优势明显
下面我们抛开游戏测试,进入GTX Titan的通用计算测试部分。我们一共选取了三款软件对GTX Titan、GTX 680、HD 7970进行测试,它们分别是ComputeMark、DirectCompute Benchmark、微软DirectX SDK。
ComputeMark号称能100%调用DirectX 11 Compute Shader的基准测试,几乎不需要CPU进行计算。DirectCompute Benchmark是早发布的针对DirectX 11 Compute Shader的基准测试软件,新的0.35版本不仅能够测试DirectCompute性能,还能测试OpenCL的性能。而微软DirectX SDK里面包含了众多测试程序,我们选取的是FluidCS11测试程序。该程序利DirectCompute性能进行流体力学的模拟,算法较为复杂,可以较为全面地考验采用不同图形架构的显卡的通用计算能力。
从测试来看,GTX Titan的优势较为明显。在ComputeMark的测试中,GTX Titan表现出了极强的统治力,在全高清分辨率、Extreme设置下领先GTX 680高达78%,相对于HD 7970也有44%的领先幅度。与此结果类似的是,GTX Titan在DirectCompute BenchmarkOpenCL、微软DirectX SDK的测试中,较GTX 680和HD 7970都有明显的性能优势。
功耗、温度、噪音: GTX Titan令人满意
尽管GTX Titan的核心规格非常恐怖,但借助热均腔板散热器、改进的28nm工艺,GTX Titan功耗、温度、噪音控制仍然达到了一个令人满意的水平。在FurMark拷机测试中,GTX Titan的待机核心温度、满载核心温度分别为29℃、81℃。重要的是在满载状态下,GTXTitan并不像其他顶级单核心显卡那样噪音较大,而是将噪音控制在一个完全能令人接受的范围,充量也就是一款中高端显卡满载时的噪音表现(同档次的GTX 680、HD 7970的满载噪音较为明显,特别是HD 7970的风扇在满载时一直处于全速运行状态)。功耗控制方面,GTX Titan所在系统的待机系统功耗、满载系统功耗分别为83W、343W,满载系统功耗只比GTX 680高了29W,比HD 7970低了22W,功耗控制非常不错。
GTX Titan出色的功耗、温度、噪音控制也延续到了GTX TitanSLI系统上,GTX Titan SLI系统的待机系统功耗、满载系统功耗分别为103W、612W。GTX Titan SLI的待机温度为32℃、30℃,满载温度为82℃、87℃,温度基本与单卡状态下一致。值得一提的是,在双卡状态下,GTX Titan SLI的噪音控制也很不错,并没有出现噪音猛增的情况。
")
{kind=link}
{kind=link}
{kind=link}
{kind=link}
属于GTX Titan的巅峰时代
这是一个好的时代,也是一个差的时代。对GTX Titan来说无疑是好的时代,它开创了一个属于它的单核心巅峰时代。请记住,它是目前为止唯一能在2560×1440、高画质、4×MSAA设置下流畅运行所有游戏大作的单核心显卡。作为一块单核心显卡,GTXTitan的晶体管数量达到了当前生产工艺的极限,堪比双核心显卡。同时,借助一些新功能、新技术,它的执行效率得到了保证。此外,噪音、温度表现它也几乎让人无可挑剔。而对于同时代的单核心旗舰显卡,甚至双核心显卡来说,无疑是差的时代,GTX Titan是那样的鹤立鸡群,远远将同时代的同档次单核心显卡抛在身后,性能比肩同时代的双核心旗舰显卡。
人类伟大的工程一般都是以体量著称的,比如万里长城、金字塔、三峡大坝、空客A380、航母战斗群、超级计算机等。如何实现这么庞大的工程以及如何使用这样庞大的设备,都需要极高的技术积累和严格的管理训练。
利用微软DirectX SDK FluidCS11可以进行流体力学的模拟,GTX Titan在其中有上佳表现

GTX Titan SLI即使在满载状态下,依然保持了不错的温度、噪音表现。
晶体管的生产也是如此,由于计算机的性能基本与晶体管数量成正比,因此晶体管数量越多就证明性能有可能越强大。设计、制造和使用数量惊人的晶体管成为展示厂商技术实力好的舞台。NVIDIA设计的GK110是目前巨大的GPU芯片,71亿个晶体管的规模本身就证明了NVIDIA在大芯片设计、大芯片制造上的实力。当然,终的物理制造是由TSMC完成的。但从芯片设计开始,NVIDIA就需要和TSMC紧密合作,确保在逼近目前民用工艺制造极限(一般会考虑成本因素)的情况下如何生产出如此庞大的芯片。从传统来看,NVIDIA从NV30开始就有意触碰当前工艺下晶体管制造的上限,虽然屡遭挫折,但也为NVIDIA积累下了无数宝贵的经验。
大芯片的制造是一方面,如何安排每一个晶体管有效运作、发挥足够的效能则是另一方面。NVIDIA在这方面披露的内容非常少,目前来看,NVIDIA在GK110以及整个开普勒架构上,使用了诸如全新的Scheduling过程、动态并行技术、Hyper-Q等全新设计来保证GPU工作的高效率。这些技术不但将GPU本身可以做好的事情做得更好,还将一些GPU本身不太擅长(比如预处理Scheduling)等转由软件在CPU中完成——虽然看起来是偷懒,但更高的工作效率证明了NVIDIA这些设计的成功。
当然,NVIDIA只揭开了GK110设计中的一小部分内容,包括基础的CUDA Core设计以及SMX设计等依旧处于“不可知”状态。甚至GPU本身的CUDA Core数量是如何统计出来的,目前依旧不得而知。但正是这种不可知状态,给业界和图形技术发展带来的震撼更大——当大家认为两家本来技术层次相当的公司在竞争,突然有一家公司抛出了似乎不是一个世代的产品,然后以更快的速度大踏步前行,这就颇为让人玩味了。
从NVIDIA为GK110预留的强大双精度能力和并行计算能力,以及GK104孱弱的双精度能力、相比GK110较差的计算能力来看,NVIDIA似乎一开始就将GK110瞄准了超级计算市场,图形性能只是其“传统优势”而已。实际上到现在GK110销售的主力对象依旧是HPC并非图形用户。我们有理由相信,GTX Titan有可能只是NVIDIA的一个孤品,不会有太多的分支产品出现——即使有,也不会像GF100时代那样拥有完整、丰富的产品序列。
GK110和GTX Titan证明了NVIDIA的技术实力,也从侧面证明了图形计算和并行计算未来发展正在按照NVIDIA的规划一步步发展。下一代Maxwell将在2014年正式和用户见面,这意味着GTX Titan还将在单核心卡皇的宝座上呆一年。

GTX Titan的发布时间问题
GTX Titan所使用的核心是NVIDIA早在去年伊始就开始曝光的GK110。在早期的传言中,这颗核心研发代号为GK100,随后由于不明原因改成GK110(很可能是设计不顺利或者流片出现重大问题,参考Fermi时代的GF100以及随后的GF110)。不过GK110由于晶体管数量众多、核
心面积巨大导致生产困难,在28nm工艺的初期阶段,TSMC很难在确保良率的前提下生产如此大一颗核心,因此改进工艺和流片试生产耗费了大量时间。随后GK110由于优秀的双精度能力以及强大的架构,又被多家超级计算机用户看中用作计算卡,NVIDIA为此提供了不少于2万颗GK110芯片成品,并一直处于持续生产、交付状态。在这种情况下,既然桌面版本GK104的产品GeForce GTX 680能够在桌面市场站稳脚跟、双芯产品GTX 690又能“稳坐第一把交椅”的情况下,NVIDIA考虑暂时不推出基于GK110核心的GeForce游戏版本的产品是符合市场规律的。毕竟GK110的计算卡Tesla K20X售价在两千美元以上,换算成人民币也至少需要两万元左右——桌面级显卡可卖不了这么多钱。因此我们推测,GK110、GK104应该是同时存在,GK110才是Kepler架构的真正旗舰产品和王者,GK104只是次一级的高端产品。只是当时NVIDIA发现GK104的性能就已经超过HD 7970,因此将GK110雪藏,并将GK104作为Kepler架构的单核心旗舰发布以对阵HD 7970。直到今天,我们才有幸见到GK110的真身——GTX Titan,Kepler架构的真正王者。
双精度对游戏有用吗?
答案是“没有”,哪怕是一丁点都没有。游戏本身全面从整数计算进入浮点计算是DirectX 9.0c时代的事情,早期的浮点计算使用的是FP16以及FP24规格,直到近期才全面进入FP32规格(依旧有大量游戏为了降低计算负荷采用FP24规格)。综合各方面因素,FP32规格是目前显卡在计算性能、工艺和终效果相权衡后的佳选择。
从性能来看,类似于GK110这样专门设计了FP64计算单元的产品,FP64浮点性能也不过比1TFlops高一些,性能难以满足高负荷下游戏运算需求(即使是FP32本身计算能力依旧不够,在特效较多的计算中计算能力依旧捉襟见肘)。对照FP32计算能力在1TFlops附近的显卡,比如经典的Radeon HD 4850,面对那些游戏大作几乎毫无还手之力。可想而知1TFlops的FP64是什么境况了。
从画质来看,在GPU进入浮点化后,FP32目前已经能够提供相当不错的计算效果。而且即使是目前的FP32,从应用角度来说开发也没有到很充足的程度,就连热门的光线追踪实际上需要更高精度的计算,可实际上主力计算引擎依旧是单精度FP32。双精度FP64计算暂时只用于尖端工业生产,民用没有太大必要。从工艺角度来看,晶体管数量和性能上限基本成正比。目前的工艺就只能提供如此多的晶体管,上限已经规划好,基本也就是GTX Titan的水平了,因此也没有办法继续拓展。FP64所需要的GPU性能太高,目前的工艺难以达到。
总的来看,FP64计算在当前阶段的应用范围仅限于工业类、HPC计算,目前我们接触到的绝大部分计算都只需要显卡的单精度计算即可。对GTX Titan这样的显卡来说,FP64双精度能力只是锦上添花的内容而已,甚至在用户整个显卡使用周期都不会有一次应用。
具体到GTX Titan上,它在默认状态下是没有开启双精度功能的。用户需要在驱动选项中选择打开双精度支持,才能获得GTX Titan的双精度能力。不过由于双精度计算部分在GTX Titan中占据了较多的晶体管,在开启双精度计算的情况下,GPU的频率控制不会沿用游戏状态下GPU Boost 2.0状态,频率反而会进一步收紧,整个加速幅度也会降低到GPU默认核心频率附近(GTX Titan在关闭双精度的游戏状态下,核心频率高甚至会超过1GHz,开启双精度后高幅度也不会超过900MHz),因此对游戏性能也有一定影响。
用户评论

